前端性能优化
1.webpack优化
- 减少webpack的打包时间
- 让webpack打包出来的文件体积更小
减小打包后文件体积
按需加载
如果我们将页面全部打包进一个 JS 文件的话,虽然将多个请求合并了,但是同样也加载了很多并不需要的代码,耗费了更长的时间。那么为了首页能更快地呈现给用户,我们肯定是希望首页能加载的文件体积越小越好,这时候我们就可以使用按需加载,将每个路由页面单独打包为一个文件。
Tree Shaking
Tree Shaking可以实现删除项目中未被引用的代码,比如
1 | // test.js |
对于以上情况,test文件中的变量b如果没有在项目中使用到的话,就不会被打包到文件中。
如果你使用 Webpack 4 的话,开启生产环境就会自动启动这个优化功能。
Scope Hoisting
Scope Hoisting 会分析出模块之间的依赖关系,尽可能的把打包出来的模块合并到一个函数中去。 比如我们希望打包两个文件
1 | // test.js |
对于这种情况,我们打包出来的代码会类似这样
1 | [ |
但是如果我们使用 Scope Hoisting 的话,代码就会尽可能的合并到一个函数中去,也就变成了这样的类似代码
1 | [ |
样的打包方式生成的代码明显比之前的少多了。如果在 Webpack4 中你希望开启这个功能,只需要启用 optimization.concatenateModules 就可以了。
1 | module.exports = { |
加快打包速度
优化 Loader
对于 Loader 来说,影响打包效率首当其冲必属 Babel 了。因为 Babel 会将代码转为字符串生成 AST(抽象语法树),然后对 AST 继续进行转变最后再生成新的代码,项目越大,转换代码越多,效率就越低。当然了,我们是有办法优化的。
首先我们可以减小 Loader 的文件搜索范围
1 | module.exports = { |
还可以将 Babel 编译过的文件缓存起来,下次只需要编译更改过的代码文件即可,这样可以大幅度加快打包时间。
1 | loader: 'babel-loader?cacheDirectory=true' |
HappyPack
受限于 Node 是单线程运行的,所以 Webpack 在打包的过程中也是单线程的,特别是在执行 Loader 的时候,长时间编译的任务很多,这样就会导致等待的情况。
HappyPack 可以将 Loader 的同步执行转换为并行的,这样就能充分利用系统资源来加快打包效率了
1 | module: { |
DllPlugin
DllPlugin 可以将特定的类库提前打包然后引入。这种方式可以极大的减少打包类库的次数,只有当类库更新版本才有需要重新打包,并且也实现了将公共代码抽离成单独文件的优化方案。
1 | // 单独配置在一个文件中 |
然后我们需要执行这个配置文件生成依赖文件,接下来我们需要使用 DllReferencePlugin 将依赖文件引入项目中
1 | // webpack.conf.js |
代码压缩
在 Webpack3 中,我们一般使用 UglifyJS 来压缩代码,但是这个是单线程运行的,为了加快效率,我们可以使用 webpack-parallel-uglify-plugin 来并行运行 UglifyJS,从而提高效率。
在 Webpack4 中,我们就不需要以上这些操作了,只需要将 mode 设置为 production 就可以默认开启以上功能。代码压缩也是我们必做的性能优化方案,当然我们不止可以压缩 JS 代码,还可以压缩 HTML、CSS 代码,并且在压缩 JS 代码的过程中,我们还可以通过配置实现比如删除 console.log 这类代码的功能。
一些小的优化点
resolve.extensions用来表明文件后缀列表,默认查找顺序是 [‘.js’, ‘.json’],如果你的导入文件没有添加后缀就会按照这个顺序查找文件。我们应该尽可能减少后缀列表长度,然后将出现频率高的后缀排在前面resolve.alias可以通过别名的方式来映射一个路径,能让 Webpack 更快找到路径module.noParse如果你确定一个文件下没有其他依赖,就可以使用该属性让 Webpack 不扫描该文件,这种方式对于大型的类库很有帮助
2.网络优化
合并资源文件,减少HTTP请求
浏览器并发的HTTP请求是由数量限制的(比如桌面浏览器并发请求可能是8个,手机浏览器是6个),如果一下子并发的几十个请求那么会有很多请求会停下来等,等前面的请求好了下一个再进去,这样就延长了整个页面的加载时间
压缩资源文件减小请求大小
文件大小越小当然加载速度就越快。 可对代码进行压缩,去掉空格、注释、变量替换,在传输时,使用gzip等压缩方式也可以降低资源文件的大小。
缓存分类
- 强缓存
- 直接从浏览器缓存中读取,不去后台查询是否过期
Expires过期时间Cache-Control:max-age=3600过期秒数
- 协商缓存
- 每次使用缓存之前先去后台确认一下
Last-ModifiedIf-Modified-Since上次修改时间EtagIf-None-Match
- 如何区别
- 是否设置了
no-cache
- 是否设置了
利用缓存机制,尽可能使用缓存减少请求
浏览器是有缓存机制的,在返回资源的时候设置一个cache-control设置过期时间,在过期时间内浏览器会默认使用本地缓存。
但缓存机制也存在一定的问题,因为网站开发是阶段性的,隔一段时间会发布一个新的版本。因为HTTP请求是根据url来定位的,如果资源文件名的url没有发生更改那么浏览器还是会使用缓存,这个时候怎么办那? 这时就需要一个缓存更新机制来让修改过的文件具有一个新的名字。 最简单的方法就是在url后加一个时间戳,但是这会导致只要有新的版本发布就会重新获取所有的新资源。 一个现代流行的方法就是根据文件计算一个hash值,这个hash值是根据文件的更新变化而变化的。 当浏览器获取文件时如果这个文件名有更新那么就会请求新的文件。
DNS预解析
现代浏览器在 DNS Prefetch 上做了两项工作:
- html 源码下载完成后,会解析页面的包含链接的标签,提前查询对应的域名
- 对于访问过的页面,浏览器会记录一份域名列表,当再次打开时,会在 html 下载的同时去解析 DNS
自动解析
浏览器使用超链接的href属性来查找要预解析的主机名。当遇到a标签,浏览器会自动将href中的域名解析为IP地址,这个解析过程是与用户浏览网页并行处理的。但是为了确保安全性,在HTTPS页面中不会自动解析
手动解析
1 | 预解析某域名 |
CDN
CDN的原理是尽可能的在各个地方分布机房缓存数据。
因此,我们可以将静态资源尽量使用CDN加载,由于浏览器对于单个域名有并发请求上限,可以考虑使用多个 CDN 域名。并且对于CDN加载静态资源需要注意CDN域名要与主站不同,否则每次请求都会带上主站的 Cookie,平白消耗流量。
使用HTTP/2.0
- 因为浏览器会有并发请求限制,在 HTTP/1.0 时代,每个请求都需要建立和断开,消耗了好几个RTT时间,并且由于TCP慢启动的原因,加载体积大的文件会需要更多的时间
- 在 HTTP/2.0中引入了多路复用,能够让多个请求使用同一个TCP链接,极大的加快了网页的加载速度。并且还支持Header压缩,进一步的减少了请求的数据大小
预加载
在开发中,可能会遇到这样的情况。有些资源不需要马上用到,但是希望尽早获取,这时候就可以使用预加载。
预加载其实是声明式的 fetch ,强制浏览器请求资源,并且不会阻塞 onload 事件,可以使用以下代码开启预加载。
预加载可以一定程度上降低首屏的加载时间,因为可以将一些不影响首屏但重要的文件延后加载,唯一缺点就是兼容性不好。
1 | <link rel="preload" href="http://example.com"> |
预渲染
可以通过预渲染将下载的文件预先在后台渲染,可以使用以下代码开启预渲染。
1 | <link rel="prerender" href="http://example.com"> |
预渲染虽然可以提高页面的加载速度,但是要确保该页面百分百会被用户在之后打开,否则就白白浪费资源去渲染。
图片优化
- 不用图片。很多时候会使用到很多修饰类图片,其实这类修饰图片完全可以用 CSS 去代替。
- 对于移动端按理说,图片不需要加载原图,可请求裁剪好的图片
- 小图使用base64格式
- 将多个图标文件整合到一张图中(雪碧图)
- 采用正确的图片格式
- 对于能够显示 WebP 格式的浏览器尽量使用 WebP 格式。因为 WebP 格式具有更好的图像数据压缩算法,能带来更小的图片体积,而且拥有肉眼识别无差异的图像质量,缺点就是兼容性并不好
- 色彩很多的使用 JPEG
- 色彩种类少的使用 PNG,有的可用SVG代替
3.CDN的缓存与回源机制解析
CDN (Content Delivery Network,即内容分发网络)指的是一组分布在各个地区的服务器。这些服务器存储着数据的副本,因此服务器可以根据哪些服务器与用户距离最近,来满足数据的请求。 CDN 提供快速服务,较少受高流量影响。
CDN的核心功能
CDN 的核心点有两个,一个是缓存,一个是回源。
- “缓存”就是说我们把资源copy一份到CDN服务器上这个过程
- “回源”就是说CDN发现自己没有这个资源(一般是缓存的数据过期了),转头向根服务器(或者它的上层服务器)去要这个资源的过程。
CDN与前端性能优化
CDN 往往被用来存放静态资源。
“根服务器”本质上是业务服务器,它的核心任务在于生成”动态页面”或返回”非纯静态页面”(需要计算的)。业务服务器仿佛一个车间,车间里运转的机器轰鸣着为我们产出所需的资源;相比之下,CDN 服务器则像一个仓库,它只充当资源的“栖息地”和“搬运工”。
所谓静态资源,就是像 JS、CSS、图片等不需要业务服务器进行计算即得的资源。而动态资源,顾名思义是需要后端实时动态生成的资源,较为常见的就是 JSP、ASP 或者依赖服务端渲染得到的 HTML 页面。
什么是非纯静态资源呢?它是指需要服务器在页面之外作额外计算的 HTML 页面。具体来说,当我打开某一网站之前,该网站需要通过权限认证等一系列手段确认我的身份、进而决定是否要把 HTML 页面呈现给我。这种情况下 HTML 确实是静态的,但它和业务服务器的操作耦合,我们把它丢到CDN 上显然是不合适的。
CDN 的实际应用
静态资源本身具有访问频率高、承接流量大的特点,因此静态资源加载速度始终是前端性能的一个非常关键的指标。
首先,CDN服务器域名与业务服务器域名不一致。
例如淘宝,业务服务器域名为“www.taobao.com”,而CDN 服务器的域名是“g.alicdn.com”
Cookie 是紧跟域名的。同一个域名下的所有请求,都会携带 Cookie。大家试想,如果我们此刻仅仅是请求一张图片或者一个 CSS 文件,我们也要携带一个 Cookie 跑来跑去(关键是 Cookie 里存储的信息我现在并不需要),这是一件多么劳民伤财的事情。Cookie 虽然小,请求却可以有很多,随着请求的叠加,这样的不必要的 Cookie 带来的开销将是很大的。
同一个域名下的请求会不分青红皂白地携带Cookie,而静态资源往往并不需要Cookie携带什么认证信息。把静态资源和主页面置于不同的域名下,完美地避免了不必要的Cookie的出现!
4.编写高性能的Javascript
常见编码规范
- 将 js 脚本放在页面底部,加快渲染页面
- 将 js 脚本将脚本成组打包,减少请求
- 使用非阻塞方式下载 js 脚本
- 尽量使用局部变量来保存全局变量
- 遵循严格模式:”use strict”;
- 尽量减少使用闭包
- 减少对象成员嵌套
- 缓存DOM节点访问
- 避免使用eval()和Function()构造器
- 尽量使用直接量取创建对象和数组
- 最小化重绘(repaint)和回流(reflow)
为什么JS要放到body尾部?
如果JS需要绑定操作DOM,那么放在header中如果处理不当就不会绑定到DOM
JS 引擎是独立于渲染引擎存在的。我们的 JS 代码在文档的何处插入,就在何处执行。当 HTML 解析器遇到一个 script 标签时,它会暂停渲染过程,将控制权交给 JS 引擎。JS 引擎对内联的 JS 代码会直接执行,对外部 JS 文件还要先获取到脚本、再进行执行。等 JS 引擎运行完毕,浏览器又会把控制权还给渲染引擎,继续 CSSOM 和 DOM 的构建。
浏览器之所以让 JS 阻塞其它的活动,是因为它不知道 JS 会做什么改变,担心如果不阻止后续的操作,会造成混乱。
结论:
- 如果JS在header中,浏览器会阻塞并等待JS加载完毕并执行
- 如果JS在body尾部,览器会进行一次提前渲染,从而提前首屏出现时间
参考demo: 执行/性能优化/testDemo/slowServer/index.js,注意查看终端
非核心代码的异步加载
- 动态脚本加载
- 使用JS创建一个script标签再插入到页面中
- defer(IE)
- 整个HTML解析完成、DOMContentLoaded事件即将被触发时才会执行,如果是多个,按照加载顺序依次执行
- async
- 加载完之后立即执行,如果是多个,执行和加载顺序无关
header中meta
兼容性配置,让IE使用最高级的Edge渲染,如果有chrome就使用chrome渲染。
1 | <meta http-equiv="X-UA-Compatible" content="IE=Edge,chrome=1"> |
如果是双核浏览器,优先使用webkit引擎
1 | <meta name="render" content="webkit"> |
使用节流和防抖
懒加载
懒加载的原理就是只加载自定义区域(通常是可视区域,但也可以是即将进入可视区域)内需要加载的东西。 对于图片来说,先设置图片标签的 src 属性为一张占位图或为空,将真实的图片资源放入一个自定义属性中,当进入自定义区域时,就将自定义属性替换为 src 属性,这样图片就会去下载资源,实现了图片懒加载。
5.浏览器渲染优化
浏览器的渲染过程,DOM 树和渲染树的区别?
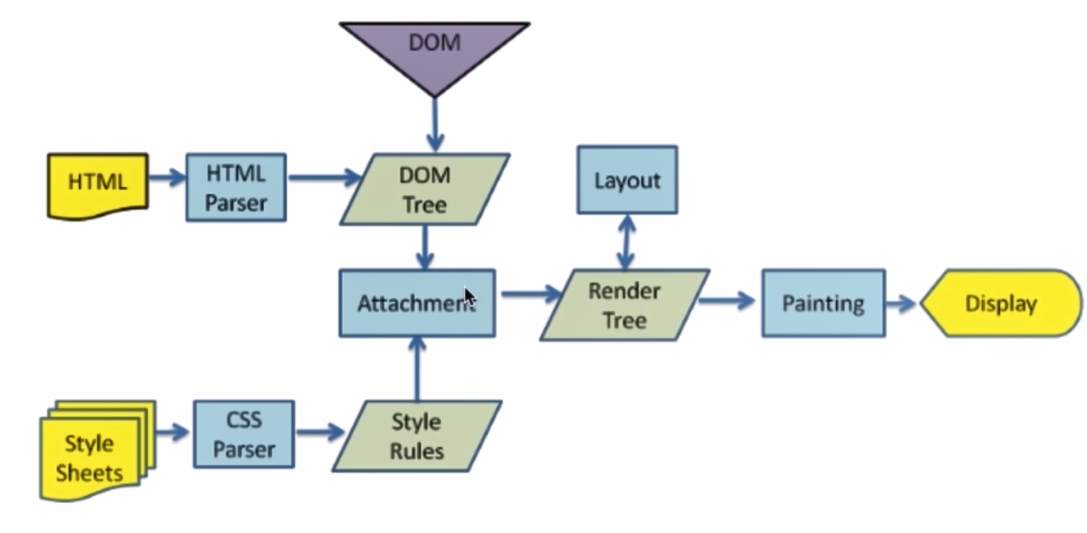
HTML 经过解析生成 DOM树; CSS经过解析生成 Style Rules。 二者一结合生成了Render Tree。 通过layout计算出DOM要显示的宽高、位置、颜色。 最后渲染在界面上,用户就看到了
浏览器的渲染过程:
- 解析 HTML 构建 DOM(DOM 树),并行请求 css/image/js
- CSS 文件下载完成,开始构建 CSSOM(CSS 树)
- CSSOM 构建结束后,和 DOM 一起生成 Render Tree(渲染树)
- 布局(Layout):计算出每个节点在屏幕中的位置
- 显示(Painting):通过显卡把页面画到屏幕上
DOM 树 和 渲染树 的区别:
- DOM 树与 HTML 标签一一对应,包括 head 和隐藏元素
- 渲染树不包括 head 和隐藏元素,大段文本的每一个行都是独立节点,每一个节点都有对应的 css 属性
CSS会阻塞DOM解析吗?
对于一个HTML文档来说,不管是内联还是外链的css,都会阻碍后续的dom渲染,但是不会阻碍后续dom的解析。
当css文件放在中时,虽然css解析也会阻塞后续dom的渲染,但是在解析css的同时也在解析dom,所以等到css解析完毕就会逐步的渲染页面了。
重绘和回流(重排)的区别和关系?
- 重绘:当渲染树中的元素外观(如:颜色)发生改变,不影响布局时,产生重绘
- 回流:当渲染树中的元素的布局(如:尺寸、位置、隐藏/状态状态)发生改变时,产生重绘回流
- 注意:JS 获取 Layout 属性值(如:offsetLeft、scrollTop、getComputedStyle 等)也会引起回流。因为浏览器需要通过回流计算最新值
- 回流必将引起重绘,而重绘不一定会引起回流
DOM结构中的各元素都有自己的盒子,这些都需要浏览器根据各种样式来计算并更具结果将元素放到它该出现的位置,这个过程叫 reflow
触发reflow
- 添加或删除可见的DOM元素。
- 元素位置改变。
- 元素的尺寸改变(包括:内外边距、边框厚度、宽度、高度等属性的改变)。
- 内容改变。
- 页面渲染器初始化。
- 浏览器窗口尺寸改变。
如何最小化重绘(repaint)和回流(reflow)?
以下几个操作会导致性能问题:
- 改变 window 大小
- 改变字体
- 添加或删除样式
- 文字改变
- 定位或者浮动
- 盒模型
解决方法:
- 需要要对DOM元素进行复杂的操作时,可以先隐藏(display:”none”),操作完成后再显示
- 需要创建多个 DOM 节点时,使用 DocumentFragment 创建完后一次性的加入 document,或使用字符串拼接方式构建好对应HTML后再使用innerHTML来修改页面
- 缓存 Layout 属性值,如:var left = elem.offsetLeft; 这样,多次使用 left 只产生一次回流
- 避免用 table 布局(table 元素一旦触发回流就会导致 table 里所有的其它元素回流)
- 避免使用 css 表达式(expression),因为每次调用都会重新计算值(包括加载页面)
- 尽量使用 css 属性简写,如:用 border 代替 border-width, border-style, border-color
- 批量修改元素样式:elem.className 和 elem.style.cssText 代替 elem.style.xxx
白屏、首屏
白屏
白屏时间指的是浏览器开始显示内容的时间,一般认为浏览器开始渲染body或者解析完head标签的时候就是页面白屏结束的时间。
计算方法:IE8-: title后输出一个时间pagestartime;
head结束前 输出一个时间firstpaint。
白屏时间=firstpaint-pagestarttime/performance.timing.navigationStart;
优化
1.加快js的执行速度,比如无限滚动的页面,可以用js先渲染一个屏幕范围内的东西
2.减少文件体积
3.首屏同步渲染html,后续的滚屏再异步加载和渲染。
首屏
首屏时间是指用户打开网站开始,到浏览器首屏内容渲染完成的时间。
计算方法:
1.模块标签标记。适用于内容不需要拉取数据才能生存以及页面不考虑图片等资源的加载情况。结束位置加时间戳输出时间。
2.统计首屏内图片加载最慢事件。 通常图片加载最慢,所以会把首屏内加载事件最慢的图片时间。
3.自定义计算
优化
首屏数据拉取逻辑放在顶部(数据最快返回)
首屏渲染css及js逻辑优先内联html,返回时能立即执行
次屏逻辑延后执行
5.SEO
前端需要注意哪些SEO
- 合理的title、description、keywords:搜索对着三项的权重逐个减小,title值强调重点即可,重要关键词出现不要超过2次,而且要靠前,不同页面title要有所不同;description把页面内容高度概括,长度合适,不可过分堆砌关键词,不同页面description有所不同;keywords列举出重要关键词即可
- 语义化的HTML代码,符合W3C规范:语义化代码让搜索引擎容易理解网页
- 重要内容HTML代码放在最前:搜索引擎抓取HTML顺序是从上到下,有的搜索引擎对抓取长度有限制,保证重要内容一定会被抓取
- 重要内容不要用js输出:爬虫不会执行js获取内容
- 少用iframe:搜索引擎不会抓取iframe中的内容
- 非装饰性图片必须加alt
- 提高网站速度:网站速度是搜索引擎排序的一个重要指标
6.雅虎军规
- 网络部分
- 尽量减少HTTP请求数
- 合并文件
- 雪碧图
- 小图Base64
- 减少DNS查找
- 开启DNS预解析
- 使用CND静态资源服务器
- 避免重定向
- 杜绝404
- 尽量减少HTTP请求数
- 缓存
- 配置ETags
- 实体标签(ETags),是服务器和浏览器用来决定浏览器缓存中组件与源服务器中的组件是否匹配的一种机制
- 添上Expires或者Cache-Control HTTP头
- 使用外链的方式引入JS和CSS(缓存)
- 配置ETags
- 内容部分
- 按需加载组件
- 预加载组件
- 减少DOM元素的数量
- 尽量少用iframe
- 压缩JavaScript和CSS(代码层面)
- CSS 部分
- 避免使用CSS表达式
- 选择
<link>而不是@import - 避免使用滤镜
- 把样式表放在顶部
- JS 部分
- 把脚本放在底部
- 去除重复脚本
- 减少DOM访问
- 图片部分
- 选用合适的图片格式
- 雪碧图中间少留空白
- 不要用HTML缩放图片,要小图就去加载小图
- 用小的可缓存的favicon.ico
- cookie
- 给cookie减肥
- 清除不必要的cookie
- cookie尽可能小
- 设置好合适的域
- 合适的有效期
- 把静态资源放在不含cookie的域下
- 当浏览器发送对静态图像的请求时,cookie也会一起发送,而服务器根本不需要这些cookie。
- 给cookie减肥
- 移动端
- 保证所有组件都小于25K
- 把组件打包到一个复合文档里
- 服务器
- 开启Gzip等压缩
- 避免图片src属性为空(为空浏览器也会向服务器发送另一个请求)
- 对Ajax用GET请求
- 尽早清空缓冲区
- 使用CDN(内容分发网络)
- 内容分发网络(CDN)是一组分散在不同地理位置的web服务器,用来给用户更高效地发送内容。